Real-time LOL Character Detection (Part 1)
Posted on : July 12, 2022 Reading Time: 10 minsReal-time LOL Character Detection (Part 1)

Objective
As an experiment to familiarize myself with element detection in images, I undertook the task of creating a program that uses Machine Learning (Python and FastAI) to detect League of Legends characters in a minimap image. The final result can be seen in the following gif.
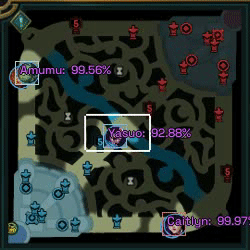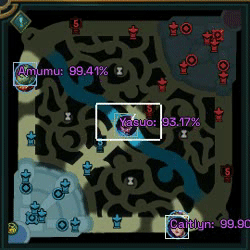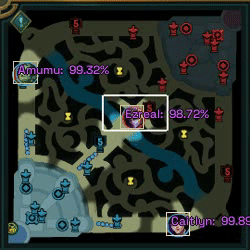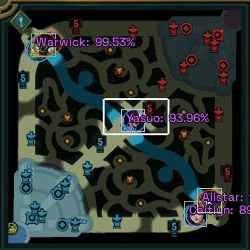
In this post there is an approach to the problem, which uses data from recorded matches to generate the training dataset, which has its problems, however, in this case I am going to use another method that gives us much more possibilities.
Dataset generation
 My approach to generate the dataset is to simplify the process as much as possible and at the same time, obtain a large dataset and that is not limited to previous matches or which characters are more used.
My approach to generate the dataset is to simplify the process as much as possible and at the same time, obtain a large dataset and that is not limited to previous matches or which characters are more used.
Therefore, we want:
- The dataset to be large enough for the model to adjust enough to the problem.
- Not limit ourselves by the characters that are in the meta.
- Ease to expand the dataset if a new champion comes out.
The solution I developed takes into account these factors, artificially generating the images with the characters in random places on the minimap. This on the one hand allows us to generate as many images as we want making the dataset virtually infinite, but it solves the problem of obtaining the bounds of each character in each image since we are the ones who determine them.
Generating the images
 The first thing to do is obtain empty minimap backgrounds, which will serve as a base to then place the character icons.
The first thing to do is obtain empty minimap backgrounds, which will serve as a base to then place the character icons.
For this I took a series of screenshots of the minimap in different states of the game, removing the characters with photoshop so that they were empty (as seen in the image above)
Once I had about 20 or 30 backgrounds, to increase randomness I made a small script that is responsible for cutting the images in a diagonal, and join each piece with the opposite diagonal of each other image, so that with n captures we get n*n images.
The process looks like this

- We take 2 images
- We rotate them 45 degrees
- We take the left half of image 1 and the right half of image 2.
- We join the 2 images.
- We rotate 45 degrees in the opposite direction.
- We cut the image so that there are no edges.
Here is the code used
from PIL import Image
def join_images(img1_route, img2_route, new_img_route):
img1 = Image.open(img1_route)
img2 = Image.open(img2_route)
# rotate imgs 45 degrees without loosing the size
img1 = img1.rotate(-45, expand=True)
img2 = img2.rotate(-45, expand=True)
# take the half left of the first and the half right of the second
img1_half = img1.crop((0, 0, img1.width//2, img1.height))
img2_half = img2.crop((img2.width//2, 0, img2.width, img2.height))
# join the two images
img_joined = Image.new('RGB', (img1.width, img1.height))
img_joined.paste(img1_half, (0, 0))
img_joined.paste(img2_half, (img1.width//2, 0))
# rotate the image back to 0 degrees
img_joined = img_joined.rotate(45, expand=True)
# crop the image so it only has the center
img_joined = img_joined.crop(
(img_joined.width//4, img_joined.height//4, img_joined.width*3//4, img_joined.height*3//4))
# save image
img_joined.save(new_img_route)At this point, we have the background images, we are missing the characters. For this, I am also going to take screenshots and cut out the character icons, in this case I took about 15, avoiding taking the edge that signals the team, we are going to add this later ourselves.

With the following script, the border is added to the images according to the color of the team that corresponds to them.
from PIL import Image, ImageDraw
base_folder = "./images/"
blue_team_imgs = "./images/blue_team/"
red_team_imgs = "./images/red_team/"
champs = ["zilean", "...rest of characters"]
for champ_name in champs:
# Get the image
champ_name = champ_name.lower()
img = Image.open(base_folder+"champ_icons/"+champ_name+".png")
w, h = img.size
zoom = 1
zoom2 = zoom * 1.8
x = w/2
y = h/2
img = img.crop(((x - w / zoom2), y - h / zoom2,
x + w / zoom2, y + h / zoom2))
offset = 2
# Add the red border
mask = Image.new('L', img.size, 0)
draw = ImageDraw.Draw(mask)
draw.ellipse(
(offset, offset, img.size[0]-offset, img.size[1]-offset), fill=255)
back = Image.new('RGBA', img.size, 0)
draw2 = ImageDraw.Draw(back)
draw2.ellipse((1, 1, img.size[0]-0.1, img.size[1]-0.1),
fill=0, outline=(232, 61, 61), width=1)
img.putalpha(mask)
img.paste(back, (0, 0), back)
# Save with the red border
img.save(red_team_imgs+champ_name.replace(" ", "")+".png")
# Add the blue border
draw2.ellipse((1, 1, img.size[0]-0.1, img.size[1]-0.1),
fill=0, outline=(19, 153, 210), width=1)
img.paste(back, (0, 0), back)
# Save with the blue border
img.save(blue_team_imgs+champ_name.replace(" ", "")+".png")
Final generation of the images
What we are going to do now is a function that generates a random image with 2 teams with random characters from those available. At the same time, we are going to obtain the bounds of each character that is not covered by another.
First I prepare a couple of variables and some utility functions
img_route = base_folder+"imgs/"
minimaps_route = base_folder+"all_minimaps/"
# Generate a list of all minimap images for quick access
map_imgs = [
Image.open(minimaps_route+x) for x in os.listdir(minimaps_route)
]
# Generate a dataframe with the names of the champs
df = pd.DataFrame({"name": ["zilean", "...rest of champs"]})
def get_teams():
"""
Returns the images and names of characters from each team
"""
# Assemble 2 teams randomly
t1 = df.sample(5).name.unique()
t2 = df.sample(5).name.unique()
t1_imgs = []
t2_imgs = []
for x in t1:
img = get_champ_img(x, "red")
t1_imgs.append(img)
for x in t2:
img = get_champ_img(x, "blue")
t2_imgs.append(img)
return t1_imgs, t2_imgs, t1, t2
def parse_extent(extent, width, height):
"""
Converts the bounds from coordinates to pixel positions
"""
return [int((extent[0])*width), int((1-extent[3])*width),
int((extent[1])*height), int((1-extent[2])*height)]
def get_random_img_name():
return str(uuid.uuid4())+".png"
I generate the images
def draw_teams(width=250, height=250):
"""
Generates a random image
"""
xmin = 0.035
xmax = 0.80
ymin = 0.035
ymax = 0.80
img_size = 0.092
DPI = 100
fig = plt.figure(figsize=(width/DPI, height/DPI), dpi=DPI)
ax = fig.gca()
map_img = random.choice(map_imgs)
plt.imshow(map_img, extent=[0, 1, 0, 1])
# Randomly get the teams
t1, t2, t1_names, t2_names = get_teams()
boundary_boxes = [[], []]
current_zorder = 50
current_positions = []
# Decide whether to show the vision rectangle or not
if random.random() < 0.97:
x = random.uniform(xmin, xmax)
y = random.uniform(ymin, ymax)
rect = patches.Rectangle(
(x, y), 0.32, 0.17, linewidth=1.2, edgecolor='white', facecolor='none', zorder=100)
ax.add_patch(rect)
# Decide whether to show the character or not
for t1_img, t1_name in zip(t1, t1_names):
if random.random() < 0.2:
continue
current_zorder -= 1
# Randomly decide the position
current_x = random.uniform(xmin, xmax)
current_y = random.uniform(ymin, ymax)
# Check if it is very attached to another character, in that case do not add it to the bounds
# because I consider it is covered
should_add = True
for pos in current_positions:
if abs(pos['x']-current_x) < 0.05 and abs(pos['y']-current_y) < 0.05:
should_add = False
break
current_positions.append({"x": current_x, "y": current_y})
current_extent = [current_x, current_x +
img_size, current_y, current_y+img_size]
if should_add:
# Add the bounds I entered
boundary_boxes[0].append(
parse_extent(current_extent, width, height))
boundary_boxes[1].append(t1_name)
# Add the character's image to the map
plt.imshow(t1_img, extent=current_extent, zorder=current_zorder)
# Decide whether to show the character or not
for t2_img, t2_name in zip(t2, t2_names):
if random.random() < 0.2:
continue
current_zorder -= 1
# Randomly decide the position
current_x = random.uniform(xmin, xmax)
current_y = random.uniform(ymin, ymax)
# Check if it is very close to another character, in that case do not add it to the bounds
# because I consider it is covered
should_add = True
for pos in current_positions:
if abs(pos['x']-current_x) < 0.05 and abs(pos['y']-current_y) < 0.05:
should_add = False
break
current_positions.append({"x": current_x, "y": current_y})
current_extent = [current_x, current_x +
img_size, current_y, current_y+img_size]
if should_add:
# Add the bounds I entered
boundary_boxes[0].append(
parse_extent(current_extent, width, height))
boundary_boxes[1].append(t2_name)
# Add the character's image to the map
plt.imshow(t2_img, extent=current_extent, zorder=current_zorder)
# Remove the edges
plt.axis([0, 1, 0, 1])
plt.axis('off')
plt.gca().set_axis_off()
plt.subplots_adjust(top=1, bottom=0, right=1, left=0,
hspace=0, wspace=0)
plt.margins(0, 0)
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.gca().yaxis.set_major_locator(plt.NullLocator())
img_name = get_random_img_name()
# plt.show()
plt.savefig(img_route + img_name, bbox_inches="tight", pad_inches=0)
plt.clf()
plt.close(fig=fig)
return boundary_boxes, img_name
Running this function in a loop we get images that are indistinguishable from the real ones and serve to train the model.

Conversion of bounds to annotation
To train the model, in addition to the images, we need a way to represent the bounds of the characters, we are going to do this with a function that converts the bounds to an xml with the format we need.
from json2xml import json2xml
def bounding_box_to_annotation(bbox, img_name):
"""
Creates the xml for the bounding box in a convoluted way
"""
data = {
"annotation":{
"folder":"imgs",
"filename":img_name,
"path":"../imgs/"+img_name,
"source":{
"database":"Unknown"
},
"size":{
"width":250, "height":250, "depth":3,
},
"segmented":0,
"object":[]
}
}
for bounds, champ in zip(bbox[0], bbox[1]):
data['annotation']['object'].append({
"name":champ,
"pose":"Unspecified",
"truncated":0,
"difficult":0,
"bndbox":{
"xmin":bounds[0],
"ymin":bounds[1],
"xmax":bounds[2],
"ymax":bounds[3]
}
})
content = json2xml.Json2xml(data, root=False, attr_type=False, item_wrap=False, ).to_xml().replace("<object>","").replace("</object>","").replace("<name>", "<object><name>").replace("</bndbox>","</bndbox></object>")
return content
The idea is that each time we generate an image, we create an xml by passing the bounds to this function and then save it in another folder with the same name as the image.
In this way we obtain 2 folders, one with the images and one with the xmls, it is very important that the name of the images and the xmls are the same since this allows FastAI to find the corresponding xmls and images, only the extension must change.

Conclusion
At this point, we can generate as many images as we want to train the model, in the next part we are going to train the model and see it in action.